Mistral AI’s latest model, Mistral Large 2 (ML2), allegedly competes with large models from industry leaders like OpenAI, Meta, and Anthropic, despite being a fraction of their sizes.
The timing of this release is noteworthy, arriving the same week as Meta’s launch of its behemoth 405-billion-parameter Llama 3.1 model. Both ML2 and Llama 3 boast impressive capabilities, including a 128,000 token context window for enhanced “memory” and support for multiple languages.
Mistral AI has long differentiated itself through its focus on language diversity, and ML2 continues this tradition. The model supports “dozens” of languages and more than 80 coding languages, making it a versatile tool for developers and businesses worldwide.
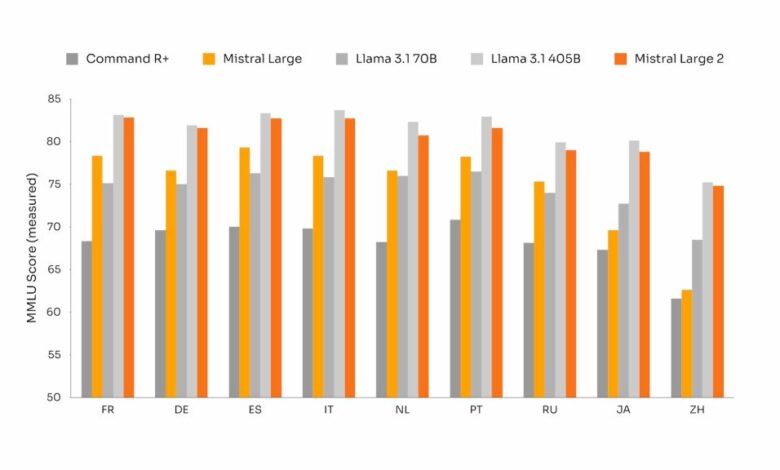
According to Mistral’s benchmarks, ML2 performs competitively against top-tier models like OpenAI’s GPT-4o, Anthropic’s Claude 3.5 Sonnet, and Meta’s Llama 3.1 405B across various language, coding, and mathematics tests.
In the widely-recognised Massive Multitask Language Understanding (MMLU) benchmark, ML2 achieved a score of 84 percent. While slightly behind its competitors (GPT-4o at 88.7%, Claude 3.5 Sonnet at 88.3%, and Llama 3.1 405B at 88.6%), it’s worth noting that human domain experts are estimated to score around 89.8% on this test.

Efficiency: A key advantage
What sets ML2 apart is its ability to achieve high performance with significantly fewer resources than its rivals. At 123 billion parameters, ML2 is less than a third the size of Meta’s largest model and approximately one-fourteenth the size of GPT-4. This efficiency has major implications for deployment and commercial applications.
At full 16-bit precision, ML2 requires about 246GB of memory. While this is still too large for a single GPU, it can be easily deployed on a server with four to eight GPUs without resorting to quantisation – a feat not necessarily achievable with larger models like GPT-4 or Llama 3.1 405B.
Mistral emphasises that ML2’s smaller footprint translates to higher throughput, as LLM performance is largely dictated by memory bandwidth. In practical terms, this means ML2 can generate responses faster than larger models on the same hardware.
Addressing key challenges
Mistral has prioritised combating hallucinations – a common issue where AI models generate convincing but inaccurate information. The company claims ML2 has been fine-tuned to be more “cautious and discerning” in its responses and better at recognising when it lacks sufficient information to answer a query.
Additionally, ML2 is designed to excel at following complex instructions, especially in longer conversations. This improvement in prompt-following capabilities could make the model more versatile and user-friendly across various applications.
In a nod to practical business concerns, Mistral has optimised ML2 to generate concise responses where appropriate. While verbose outputs can lead to higher benchmark scores, they often result in increased compute time and operational costs – a consideration that could make ML2 more attractive for commercial use.
Compared to the previous Mistral Large, much more effort was dedicated to alignment and instruction capabilities. On WildBench, ArenaHard, and MT Bench, it performs on par with the best models, while being significantly less verbose. (4/N) pic.twitter.com/fvPOqfLZSq
— Guillaume Lample @ ICLR 2024 (@GuillaumeLample) July 24, 2024
Licensing and availability
While ML2 is freely available on popular repositories like Hugging Face, its licensing terms are more restrictive than some of Mistral’s previous offerings.
Unlike the open-source Apache 2 license used for the Mistral-NeMo-12B model, ML2 is released under the Mistral Research License. This allows for non-commercial and research use but requires a separate commercial license for business applications.
As the AI race heats up, Mistral’s ML2 represents a significant step forward in balancing power, efficiency, and practicality. Whether it can truly challenge the dominance of tech giants remains to be seen, but its release is certainly an exciting addition to the field of large language models.
(Photo by Sean Robertson)
See also: Senators probe OpenAI on safety and employment practices

Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
The post Mistral Large 2: The David to Big Tech’s Goliath(s) appeared first on AI News.


