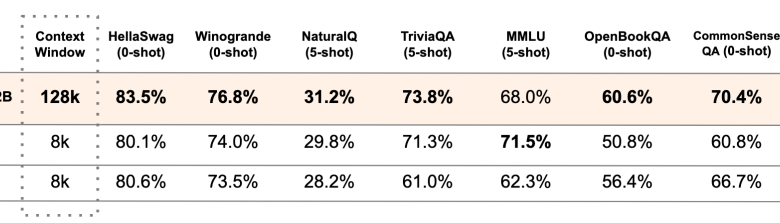
Mistral AI has announced NeMo, a 12B model created in partnership with NVIDIA. This new model boasts an impressive context window of up to 128,000 tokens and claims state-of-the-art performance in reasoning, world knowledge, and coding accuracy for its size category.
The collaboration between Mistral AI and NVIDIA has resulted in a model that not only pushes the boundaries of performance but also prioritises ease of use. Mistral NeMo is designed to be a seamless replacement for systems currently using Mistral 7B, thanks to its reliance on standard architecture.
In a move to encourage adoption and further research, Mistral AI has made both pre-trained base and instruction-tuned checkpoints available under the Apache 2.0 license. This open-source approach is likely to appeal to researchers and enterprises alike, potentially accelerating the model’s integration into various applications.
One of the key features of Mistral NeMo is its quantisation awareness during training, which enables FP8 inference without compromising performance. This capability could prove crucial for organisations looking to deploy large language models efficiently.
Mistral AI has provided performance comparisons between the Mistral NeMo base model and two recent open-source pre-trained models: Gemma 2 9B and Llama 3 8B.

“The model is designed for global, multilingual applications. It is trained on function calling, has a large context window, and is particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi,” explained Mistral AI.
“This is a new step toward bringing frontier AI models to everyone’s hands in all languages that form human culture.”
Mistral NeMo introduces Tekken, a new tokeniser based on Tiktoken. Trained on over 100 languages, Tekken offers improved compression efficiency for both natural language text and source code compared to the SentencePiece tokeniser used in previous Mistral models. The company reports that Tekken is approximately 30% more efficient at compressing source code and several major languages, with even more significant gains for Korean and Arabic.
Mistral AI also claims that Tekken outperforms the Llama 3 tokeniser in text compression for about 85% of all languages, potentially giving Mistral NeMo an edge in multilingual applications.
The model’s weights are now available on HuggingFace for both the base and instruct versions. Developers can start experimenting with Mistral NeMo using the mistral-inference tool and adapt it with mistral-finetune. For those using Mistral’s platform, the model is accessible under the name open-mistral-nemo.
In a nod to the collaboration with NVIDIA, Mistral NeMo is also packaged as an NVIDIA NIM inference microservice, available through ai.nvidia.com. This integration could streamline deployment for organisations already invested in NVIDIA’s AI ecosystem.
The release of Mistral NeMo represents a significant step forward in the democratisation of advanced AI models. By combining high performance, multilingual capabilities, and open-source availability, Mistral AI and NVIDIA are positioning this model as a versatile tool for a wide range of AI applications across various industries and research fields.
(Photo by David Clode)
See also: Meta joins Apple in withholding AI models from EU users

Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Source link


